Somewhere in your bank statement is a line like
KLARNA* HMSVERIGE SE SEK. It's an H&M purchase. Every budgeting
app, expense tracker, and fraud model has to decode lines like that into
merchant names, millions of times a day, and the obvious prompt for the job
gets 64% of our labeled examples right. So we pointed EigenPrompt at it and
let it search. The winning prompt scores 81%, fits on one line, and costs 41%
less per call than the one it replaced. Finding it took 41 minutes and about
80 cents of API spend.
This article shows how we applied EigenPrompt to that entity-resolution problem and compares what its Efficient, Standard, and Advanced optimization modes each bought. The companion guide shows the exact screens, settings, and files needed to reproduce the Standard run.
Executive Summary
Standard mode improved exact-match merchant resolution from 64% to 81% while cutting the winning prompt's per-call cost by 41%.
Advanced mode reached the highest score, 83%, and also found a one-line prompt twelve points above its baseline for less than half the baseline's cost.
The quality-analysis review tables exposed where remaining errors came from: punctuation, sub-brand granularity, payment rails, app-store billing, delivery platforms, and rebrands.
Jump to a section
-
Key issues with entity resolution
-
Case study overview
-
Results by optimization mode
-
Step-by-step reproduction guide
One scope note before we start: for this demo we deliberately used only low-cost, mid-tier models — an open-weight
gpt-oss-120bserved on Groq as the target, with two fast open-weight models doing the optimizing. The method is identical on bigger models; it just costs more to run.
Key issues with entity resolution
The task sounds simple: read a transaction descriptor and return one merchant name.
Transaction: TST*BLUE BOTTLE UNION SQ
Expected output: Blue Bottle Coffee
But the hard cases are exactly the ones that show up in real statements, and every one below is a row in the dataset we used:
- A processor is visible, but the processor is not the merchant:
STRIPE* LINEARAPP INCis Linear. - App-store billing hides the underlying service:
APPLE.COM/BILL DUOLINGOis Duolingo, not Apple. - A delivery platform is the actual counterparty:
UBER EATS *TACOBELL 312resolves to Uber Eats, not Taco Bell. - A buy-now-pay-later rail stands in front of the retailer:
KLARNA* HMSVERIGE SE SEKis H&M. - A rebrand sits half-finished in the descriptor:
TWITTER BLUE X CORP SF CAis X. - Something that looks like line noise isn't:
ACH PAYROLL ADPFIDES 12345is ADP.
Two of those rules point in opposite directions: the delivery platform counts as the merchant; the app store doesn't. The labels take a position on every case like this, and the prompt's job is to learn that position, not argue its own.
The rule the prompt has to enforce: return the primary canonical merchant or
service, and return Unknown when the descriptor doesn't contain enough
evidence to name one.
Case study overview
The example uses the entity-resolution dataset published in the eigenprompt-resources repository:
samples/entity-resolution/dataset.csv
samples/entity-resolution/dataset.json
It has 140 rows and two columns: the raw descriptor and the expected merchant.
The labels are picky on purpose. They want Dunkin' with the apostrophe,
Apple TV+ with the plus, and Amazon Marketplace rather than just Amazon
when that's what the descriptor says. Exact-match scoring means close doesn't
count, which is also how a downstream system would consume this output.
The starting prompt is the one most people would write first:
Identify the primary merchant from this bank transaction description.
Transaction: {{INPUT}}
Output only the canonical merchant name (e.g., 'Amazon', 'Starbucks', 'Netflix').
If no merchant can be determined, output 'Unknown'.
Results by optimization mode
We ran the same prompt, dataset, and target model (groq/openai/gpt-oss-120b)
through three of EigenPrompt's optimization modes: Efficient, Standard, and
Advanced. The Standard run improved accuracy from 64% to 81%, and its winning
prompt costs $0.0151 per thousand calls against the baseline's $0.0254 — 17
points better and 41% cheaper at once. The Advanced run pushed the top score to
83% and turned up a one-line prompt twelve points above its baseline for less
than half the baseline's per-call cost. Efficient, a five-minute pass, added
five points for under fifty cents of API spend.
One footnote before the table: each row reports the baseline measured inside that run, so the same starting prompt appears as 69%, 64%, and 67%. Same prompt, same dataset, same task. LLM calls still carry a few points of run-to-run noise, which is why the frontier and the held-out examples matter more than any single baseline number.
| Mode | Baseline → best | Best prompt cost / 1k | Cheapest at/above baseline | Candidates | Optimization time |
|---|---|---|---|---|---|
| Efficient | 69% → 74% | $0.0403 | $0.0178 at 69% | 23 | 5m 7s |
| Standard | 64% → 81% | $0.0151 | $0.0092 at 67% | 48 | 40m 47s |
| Advanced | 67% → 83% | $0.0601 | $0.0102 at 71% | 116 | 2h 21m 46s |
The frontier charts tell the same story in pictures. In each one the gold diamond is the baseline, blue points are the frontier, grey points are dominated (beaten on both quality and cost by something on the frontier), and point size encodes latency.
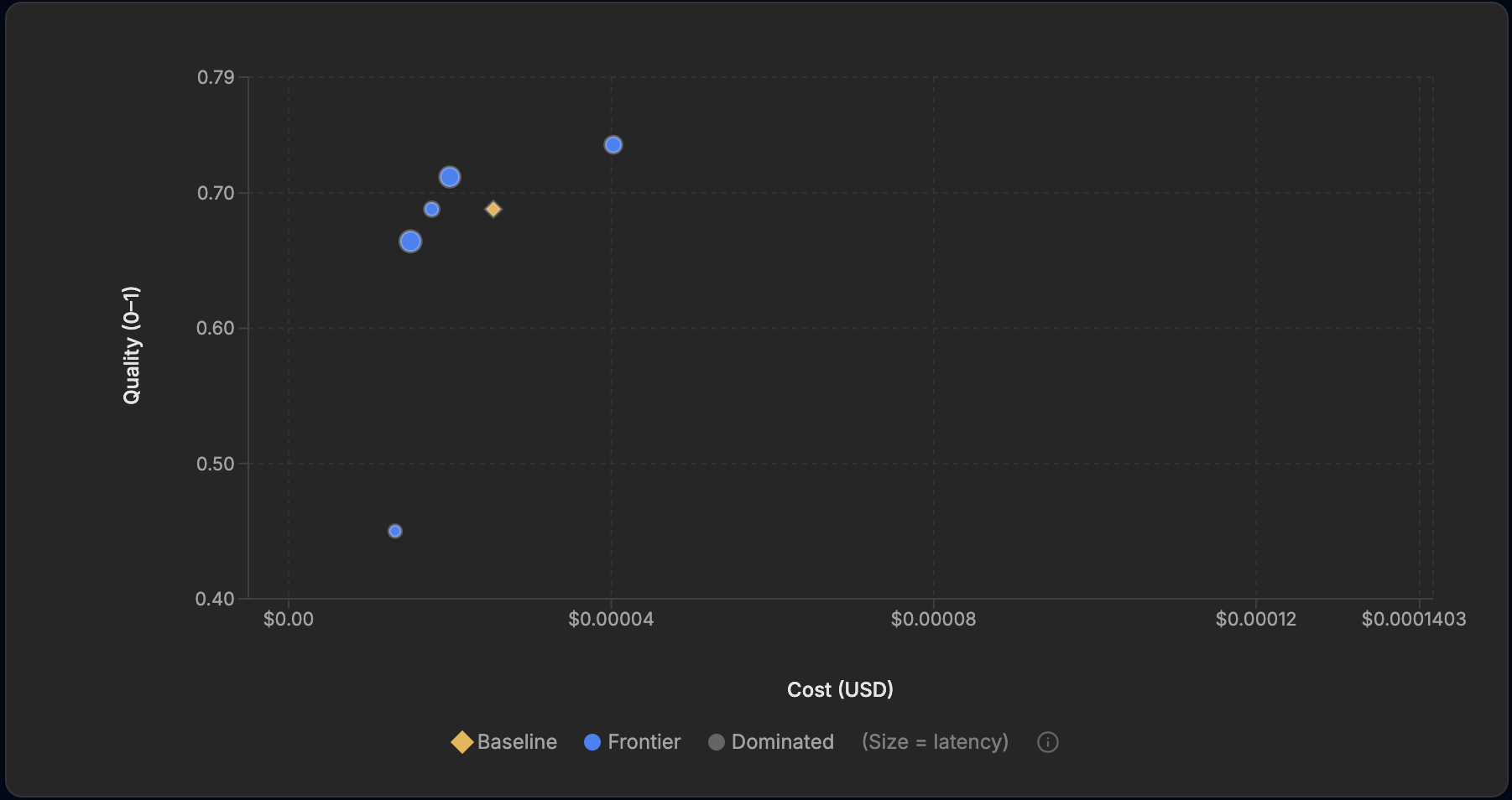
The Efficient run: five frontier points after five minutes of search. The blue point at the baseline's height but to its left matches the baseline's 69% for 30% less cost.
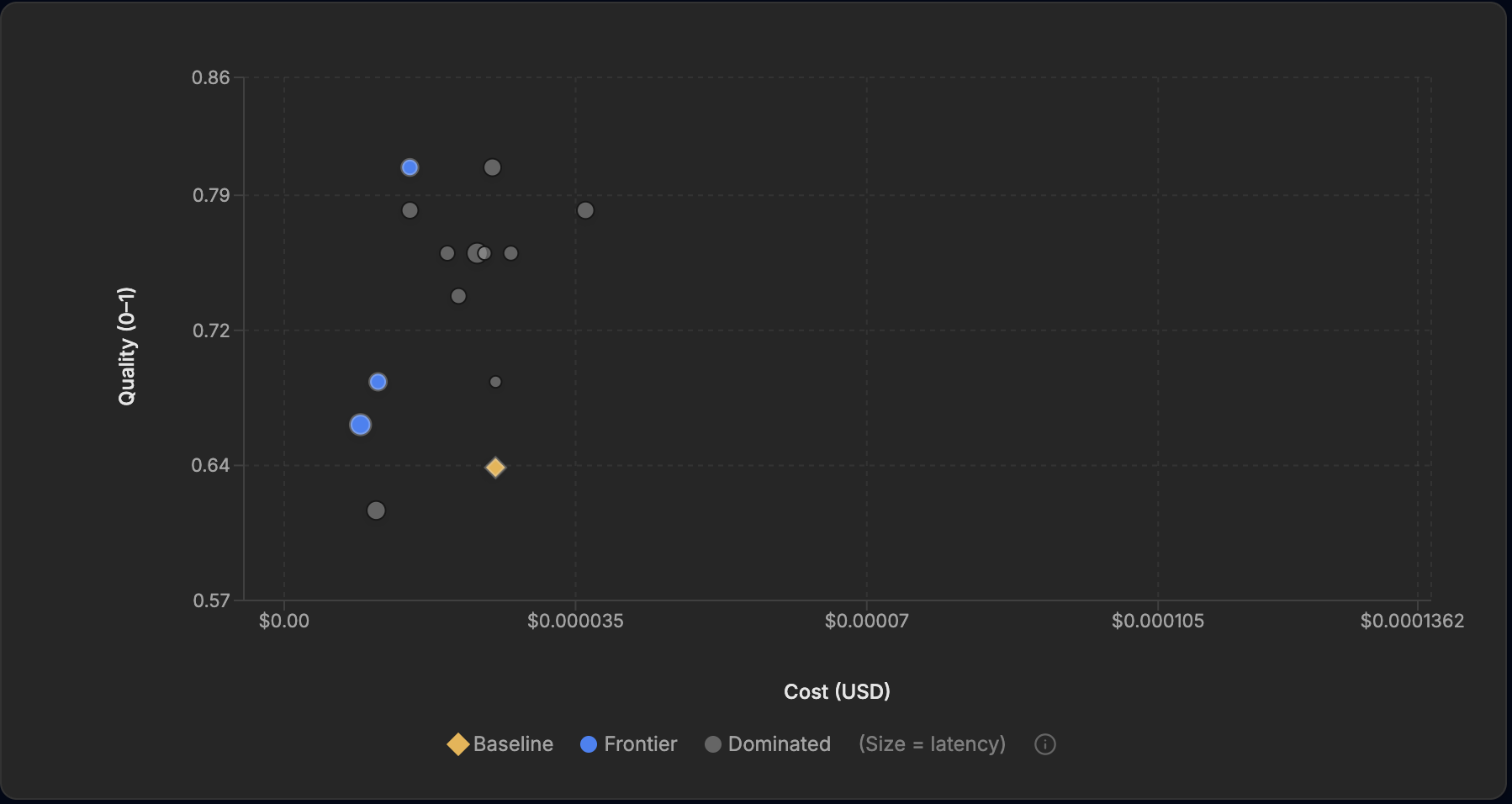
The Standard run. The top frontier point sits above and to the left of the baseline: 81% quality at 59% of the baseline's cost. Note the grey point at the same height further right — a second 81% prompt, dominated because it does the same job for two-thirds more money.
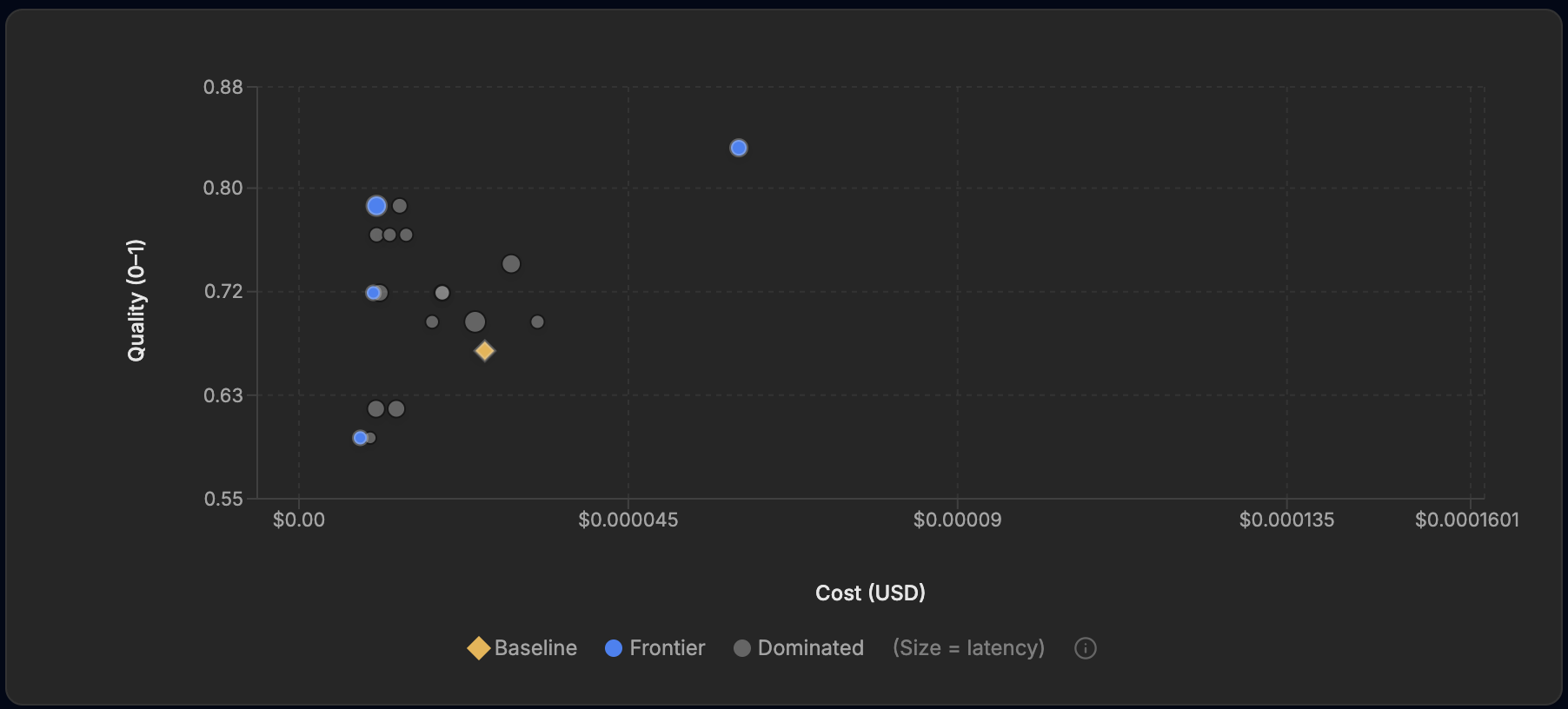
The Advanced run. The 83% point pays for its accuracy out on the right; the quietly impressive point is the 79% one near the left edge, twelve points above the baseline at well under half its cost.
What EigenPrompt is optimizing
EigenPrompt is not training a model. It is searching over prompts. For each candidate prompt it runs the merchant-extraction task over the evaluation data, scores the output against the expected merchant, measures cost and latency, and keeps the prompts that nothing else beats on both quality and cost.
That surviving set is the Pareto frontier. A frontier point can be more accurate, cheaper, or faster than its neighbours, but no frontier point is strictly worse than another on every metric. This is why a good optimization run hands you a menu rather than a single magic prompt: you pick the point that fits your accuracy, cost, and latency budget, knowing what each step along the curve costs.
How to reproduce the Standard run
The exact click-by-click setup now lives in a companion guide. It covers the dataset, baseline prompt, exact-match scoring, target and optimizer models, Standard-mode settings, cost and time caps, and the result screens to inspect when the run finishes.
What changed from Efficient to Advanced
The three modes are the same machine at three throttle settings, and the runs behave accordingly.
Efficient is the five-minute, five-point probe. With 23 candidates it nudged the top score from 69% to 74% and matched the baseline's accuracy at 30% less cost. Its best prompt is recognizably a human style of prompt: a careful paragraph telling the model to ignore store numbers, addresses, and transaction metadata. For about $0.46 of API spend, it answered the question that matters before spending more: this prompt has headroom.
Standard is the workhorse: 64% to 81%, with the winner cheaper than the baseline, in 41 minutes. The companion guide shows the exact setup that produced this run.
Advanced ran 116 candidates over 2h 21m 46s and found the best prompt of the series at 83%, for $2.37 of API spend ($1.26 on target-model evaluation, $1.11 on the optimizer models). It looks nothing like a prompt a person would write on the first try:
<context>Merchant Entity Resolution</context>
<task>Extract the canonical merchant brand name from the input.</task>
<input>{{INPUT}}</input>
<constraints>
- Map the input to the official, standard brand name.
- If the merchant is unrecognizable, return "Unknown".
- Maintain exact casing, spacing, and punctuation (e.g., "H&M", "Dunkin'", "Apple TV+", "Uber Eats", "Microsoft Azure", "Blue Bottle Coffee").
</constraints>
<output_format>
Brand name string only. No explanations, no quotes, no trailing punctuation.
</output_format>
Look at the constraint about casing and punctuation, then look back at the task's hard cases. H&M, Apple TV+, and Blue Bottle Coffee are names straight out of the Standard run's review queue. Nobody fed the optimizer those failures. The Advanced search rediscovered the pattern on its own, wrote a rule for it, and picked its own examples. That is what the 3–5x price tag buys: a search wide enough to converge on the structure of the task's errors.
The counterweight is cost. The 83% prompt is long, and at $0.0601 per
thousand calls it runs about 2.4 times the baseline's price. But the same
frontier carries the opposite trade: Get canonical merchant for {{INPUT}}; reply brand name or “Unknown”. scores 79% — twelve points above the Advanced
run's baseline — at $0.0106 per thousand, about 42% of what the baseline
costs. Everything here is fractions of a cent because the target model is
cheap; the ratios are what carry to bigger models and bigger volumes.
The wider search paid off twice: a new top score at 83%, and a one-line prompt twelve points above baseline at less than half the baseline's cost.
Takeaways
- Entity resolution is resolution, not string cleanup. The merchant hides behind payment rails, BNPL providers, app-store billing, delivery platforms, and rebrands. A prompt that handles the easy rows tells you nothing about these.
- Exact match is unforgiving, and that's the point. Apostrophes, spaces,
and sub-brands all cost real points. The quality-analysis tables turn each
lost point into a reviewable row, and whether a label should say
PaneraorPanera Bread,AmazonorAmazon Marketplace, is a decision your team should make on purpose, not discover in production. - The frontier matters more than the top score. The Standard run's value wasn't one 81% prompt; it was 81% at 59% of base cost and 67% at 36% of base cost in the same result, with the trade-off laid out for choosing rather than guessing.
- The mode dial is a budget decision, not a quality gamble. Efficient told us in five minutes the prompt had headroom. Standard banked most of the gain. Advanced bought the highest score plus the best cheap prompt. The improvement guarantee holds at every setting: no better prompt found, no credit spent.